
Preface: What is Duplicate Content?
Duplicate Content is content that exists across multiple sites on the Internet. From here, it means a URL. So if your site’s content is found in a few URLs, you have a problem with duplicate content. in this article, we show you how to fix the duplicate content problem? (for example rel = canonical tag)
While duplicate content may not penalize your site, it can often lead to your site ranking down in search results. When there is roughly the same content in multiple URLs, it becomes difficult for Google to show which of these URLs to users when searching.
Why is Duplicate Content important?
Frequent content is important to search engines and site owners.
From the search engines point of view
Duplicate content causes three major problems for search engines:
- They don’t know which version of content to include in their main index.
- They do not know how to allocate content to one address or to divide it among them all.
- They do not know which of the addresses to display in the SERP (search results page).
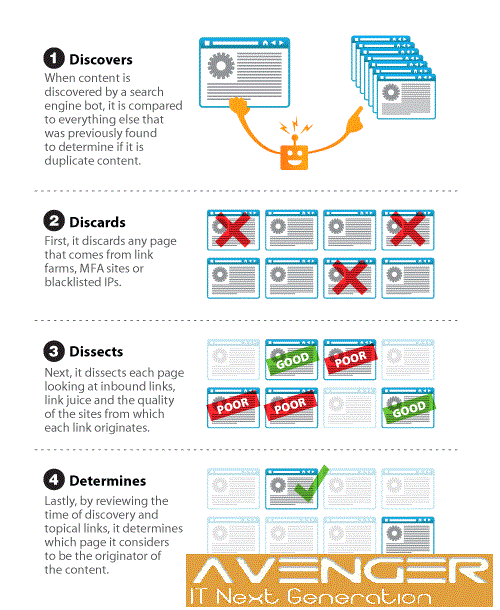
From the website owners’ point of view
When duplicate content is created on-site, site owners will be hit by a drop in site rankings. This is divided into two parts:
- Search engines rarely display multiple versions of the same content for best results, so they have to select one of the few contents on the site. This reduces the display of any duplicate content in the search results.
- Other sites also have to select one of several versions of the links, which reduces the value of backlinks. In this case, instead of websites linking to only one copy of the content, it will inadvertently link to several URLs of that content, thereby reducing the credibility of the backlinks. Because backlinks are one of the factors for ranking a page, it negatively affects the number of times content is displayed in search results.
Overall: Your site’s content is not performing well and competitors who do not have duplicate content outperform you.
How does the duplicate content problem SEO arise?
In many cases, site owners have no role in generating duplicate content. But that doesn’t mean it’s not. The fact is that on average, 29% of the web is duplicate content.
Here’s a look at the factors behind duplicate content that are often unwanted:
1. URL Changes
Parameters in URL pages are one of the most important factors in creating duplicate content. Both the parameters themselves and the sequence of their creation in the URL cause this problem.
Example:
- ULW www.widgets.com/blue-widgets?color=blue is a duplicate of ULW www.widgets.com/blue-widgets.
- ULR www.widgets.com/blue-widgets?color=blue&cat=3 Duplicate of ULW www.widgets.com/blue-widgets?cat=3&color=blue.
Also, the IDs that are generated by any user link to a website in a URL can cause duplicate content. In this case, each user is assigned an ID after logging in and this ID appears in the URL.
Print versions of pages also cause duplicate content, thereby generating multiple versions of an index page.
2. Http and Https versions or versions with www and without www
If your site has both www and non-www versions at www.site.com and site.com and there is content in both versions, you simply create duplicate content. This also applies to Http and https versions of the site. If both versions of the site are executed and viewed, they represent duplicate content.
3. Copied content
Site content doesn’t just include posts or pages with your content. Information on your product page is also part of the site content. Copywriters may steal your posts when they are published and publish them on their site. Many online stores also use the information provided by their manufacturer in product descriptions. This description has probably been used by other sites as well. Both are duplicate content.
How to fix the duplicate content problem?
Solving Duplicate Content Problems Begins with the idea of which addresses are the correct content addresses. When submitting content to multiple URLs, search engines need to know which URL is correct. There are three ways to do this: Using the redirect 301 to the correct URL, the rel = canonical tag or using Google’s parameter control section in its search console.
Redirect 301
In many cases, the best way to use duplicate pages is to redirect to the homepage. When you redirect multiple pages to the same page, the page value increases in competition with other pages on other sites. As a result, the page rank is improved in search results.
Rel = canonical
Another way to deal with duplicate content is to use the rel = canonical tag on duplicate pages. This tag tells search engines that these pages are a copy of a homepage and that their credentials should be transferred to that homepage.
The rel = canonical tag is actually part of the site’s HTML code and looks like this:
[jv_label background_color = "# 09c" font_size = "13" border_radius = "0" text_color = "# ffffff"] <head> ... [other code that might be in your document's HTML head] ... <link href = "/ URL OF ORIGINAL PAGE" rel = "canonical" /> ... [other code that might be in your document's HTML head] ... </head> [/ jv_label]
The rel = canonical tag should be added to the header of the HTML code for all duplicate pages and the original URL should also be specified. Be sure to include quotations. Like Redirect 301, this tag transfers almost all page credentials to the homepage, and because it runs at the page level (not at the server level), it takes less time to make an impact.
Using the MozBar plugin in the Chrome browser, you can view the original URL of each page you are in as shown below.
Meta Noindex
The meta tag that is very useful in Abanjah and can be useful in dealing with recurring pages is the Robots meta tag with the value “noindex, follow”. Putting this tag in the header of duplicate pages can prevent them from being indexed by search engines.
The general format of this meta tag is as follows:
[jv_label background_color = "# 09c" font_size = "13" border_radius = "0" text_color = "# ffffff"] <head> ... [other code that might be in your document's HTML head] ... <meta name = "robots" content = "noindex, follow"> ... [other code that might be in your document's HTML head] ... </head> [/ jv_label]
This meta tag allows search engines to monitor links within duplicate pages but not index them. Giving access to Google is important for monitoring duplicate pages, even if you tell Google not to index it. Google has tacitly stated that it should not restrict the accessibility of its robots to scrolling pages, though. Search engines are interested in seeing everything on the site. This capability allows them to make the right decisions under ambiguous circumstances.
Using indexing in pages like pagination is very useful and prevents duplicate content.
Preferred Domain and Parameter Control in Google Search Console
The Google Search Console allows site owners to choose between the version with www and without www, their chosen version for monitoring and indexing by Google robots. Parameters that do not need monitoring can also be specified in the relevant section.
Depending on the URL structure of your site and the factors behind duplicate content creation, using preferred URLs and parameter control strategies can be very effective.
The main drawback of using parameter controls as the only solution to the duplicate content problem is that this system only applies to Google and that any rules defined there are not seen by other search engines such as Bing. For this reason, you should go to the webmaster of each of the search engines and make the settings to control the parameters.
Other solutions to the duplicate content problem
- Use a fixed format when using internal links on the site. For example, if the selected version of your site is without www, write all internal links without www and avoid using versions with www.
- When using site links on other sites make sure to use the original copy of the links and avoid using duplicate links.
- To create an extra layer of security for your content when copying is stolen, also use the canonical tag on the homepage. This will counteract the effect of the copyrighted material on its thieves. While not all copywriters use page code to copy the content, many still use the technique. Applying the canonical tag will counteract the effect of content copying by those who use page code.
Conclusion
In summary: Having duplicate content can affect your site in a variety of ways; but unless you’ve been duplicating deliberately, it’s unlikely that one of those ways will be a penalty. This means that:
You typically don’t need to submit a reconsideration request when you’re cleaning up innocently duplicated content.
If you’re a webmaster of beginner-to-intermediate savviness, you probably don’t need to put too much energy into worrying about duplicate content, since most search engines have ways of handling it.
You can help your fellow webmasters by not perpetuating the myth of duplicate content penalties! The remedies for duplicate content are entirely within your control. Here are some good places to start.
ABOUT US
Working with Digital marketing, SEO services, and website design with a highly experienced team for years, َAvenger IT Next Generation has been able to meet the needs of people in various businesses and help businesses grow. Continuously updating their level of knowledge and exploring different markets has surpassed the pioneers in this field and incorporate successful experiences into their careers.
Avenger IT Next Generation is a website design and development agency and an SEO agency to promote your business, call with us.
