
Preface: What is a Robots.txt file? What effect does SEO have?
The Robots.txt file is a text file that webmasters can use to guide search engine robots when monitoring a website. The robot.txt file is part of a protocol called REP that standardizes how robots monitor the web and how to access and index content and provide it to users. The REP protocol also includes how to handle the Robots meta tag and other commands such as phallus links.
In effect, robots text files tell user agents (such as search engine robots) which pages to monitor and which paths to work with. These are given in the form of instructions like Allow and Disallow.

The basic format of this file is as follows:
User-agent: [user-agent name] Disallow: [URL that should not be monitored]
This file allows you to write different commands for different user agents. It is enough to distinguish each set of commands for one user agent with a dash. Notice the following image:

If multiple sets of commands are created for multiple user agents in the robots.txt file, each user agent reads its instructions. Consider the following example:

Given the above commands, the user agent named msnbot only looks at the set of commands in Part I. If the user agent logged in to the site is none of these options, follow the instructions in Part Two that started with user-agent: *.
Examples of robots.txt file
Here are some examples of the robots text file. Note that this file is located on the root of the site, www.example.com/robots.txt.
Block All Webmasters from Accessing the Whole Website:
User-agent: * Disallow: /
These commands in the robots.txt file tell-all web browsers not to monitor any page in the www.example.com domain.
Access all site pages to all monitors:
User-agent: * Disallow:
These commands in the robots text file tell-all web browsers that they can monitor all pages of the www.example.com domain.
Block access to a specific monitor from a specific folder:
User-agent: Googlebot Disallow: / example-subfolder /
These commands tell the Googlebot Monitor that the URLs included at www.example.com/example-subfolder/ are not monitored.
Block access to a specific webpage from a particular webpage:
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
These commands tell Bingbot Monitor (Bing Monitor Robot) not to monitor the URL only www.example.com/example-subfolder/blocked-page.html.
How does the robots.txt file work?
Search engines have two main tasks:
- Web monitoring to find new content
- Indexing the content for the searchers they are looking for
Search engines for monitoring websites follow links and go from site to site. This behavior is also called crawling or spidering.
Once they reach a website, they look at the robots text file before monitoring it. If you find this file, read it and then continue monitoring the website. Robots.txt files are the guidelines for webmasters to monitor the web. If the robots.txt file has no command to restrict the searchers (or there is no robots.txt file at all), the searchers will index and index all the found sections without any restrictions.
Complementary information about robots.txt file
- The robots text file must be located at the root of the site to be found by the monitors.
- The Robots.txt file is case-sensitive. That is, the correct name of this file is robots.txt. (Shapes like robots text are not acceptable)
- Some robots may override the robots text file instructions. This is more the case with untrusted monitors such as email-finding robots.
- The robots.txt file is publicly available. In other words, anyone can see their commands. So don’t put your private information there.
- Each subdomain of the website must have its robots text file. In other words, blog.example.com and example.com should each have their separate robots text file.
- You can use the # character at the beginning of the description to insert a comment.
- The maximum size available for a robots.txt file is 500 KB. Keep the volume below this number.
- The path to the sitemap can be placed at the bottom of the robot’s text file as shown below.

We will discuss each of these points further.
Supported commands in robots.txt file
There are generally five types of commands for this file, including:
- User-agent: refers to a particular monitor (often called search engine robots). A list of common user agents can be found here.
- Disallow: A command to block access to a part of a website. Only one Disallow statement can be used per line.
- Allow: This command tells Googlebot that it can access a subdirectory address, even if its main collection path is blocked in another line from the robots.txt file.
- Crawl-delay: refers to the time that the crawler must wait before loading the page’s content. Of course, this command is often ignored by Google.
- Sitemap: refers to XML sitemaps. Note that this command is only supported by Google, Ask, Bing and Yahoo.
Pattern matching
Robots.txt file commands can also be a bit complicated when creating a template to cover a range of URLs. Google and Bing support regular expressions when used in a robots text file, and SEO experts can make optimum use of them. The usual two characters here are * and $.
- Character * Used to indicate the existence of any character at the beginning, end or middle of an address.
- The $ character is also used to indicate the completion of a URL.
Google has compiled a list of matching patterns and examples here.
Prioritize robots.txt commands
When multiple commands are applied to a URL, the command with the most characters is accepted. For example, let’s see what happens to the “/home/search/shirts” URL with the following robot.txt file:
Disallow: / home Allow: * search / * Disallow: * shirts
In this scenario, the URL will be monitored because the Allow command has 9 characters. While the Disallow command has only 7 characters. If you want this block to be blocked, you can increase the characters of the Disallow command as follows:
Disallow: ******************* / shirts
Also, if the number of characters is equal, the Disallow command is given priority. For example, “/search/shirts” will be blocked according to the following instructions:
Disallow: / search Allow: * shirts
Where should the robots.txt file be?
Search engines and other web browsers, after logging into a site, know they must look for a robots text file. But they are looking for this file only in a specific path (the root of the website). If a web browser at www.example.com/robots.txt does not see any files, they assume that there is no robots.txt file on this website.
Even if this file exists in other ways, the monitor won’t notice it. So, for sure, we emphasize that you put it on the root of the website.
Why does your website need a robots.txt file?
The robots.txt file can be used to manage the accessibility of the monitors on the website. While this may be a little risky if you make a mistake, it is also very effective.
Some of the positive uses of the robots text file include:
- Avoid duplicate content problem (note that in most scenarios meta robots are the best option)
- Keeping part of the website private (e.g. site administration section)
- Prevent indexing web pages of internal search results
- Refer to the web site map
- Prevent indexing of some files (such as PDFs) on the website
- Delaying website monitoring to avoid excessive strain on the webserver
- Crawl Budget Optimization
If there is no section on your website to hide your search results, it may be best to override the robots.txt file.
Hidden items by robots.txt
Using the robots text file you can hide some of the site’s links from the search engines. The pages that can be mentioned here are:
- Duplicate content pages
- Second Pages Next Categories
- Dynamic URLs of products or categories
- User Profile Pages
- Admin Pages
- Shopping Cart Page
- User talk page
- Thanksgiving page
- Search page
Check for robots.txt file
Not sure about robots text file on your website? Just add the phrase robots text to the end of your domain name and enter the final URL in your browser. If no text page appears, then there is no such file on your site.
How to create robots.txt file?
If the robots text file doesn’t exist on your website, don’t worry. It’s easy to make. You can only create a robots.txt file on the site using these commands and then test it using the Google search engine’s robots text tester tool.
SEO tips about robots.txt file
Here’s a look at some tips on how to build a robots text file that will improve your website’s SEO.
- Make sure the main content of the site is not blocked.
- Links to pages blocked by the robots text file will not be followed. This means that if there is no link to it anywhere or on a page not blocked from your website, it will not be indexed by the search engines. Secondly, no credit will be transferred from the blocked page to its links. If you have pages that do not need to be indexed, then you should look for another mechanism.
- Never use a robots text file to hide sensitive and private website data from search results. Because such links may be located elsewhere on the site and users may access them. A better way to prevent such pages from being accessed is to set up a password for access.
- Many search engines have multiple user agents. For example, Google uses Googlebot for organic search. It also uses Googlebot-Image to search for images on websites. Most user agents use a single search engine, the same general instructions for one user agent and do not need to define different commands for each. But if you need different command definitions for different user agents, you can define them in the robots.txt file.
- Search engines crawl the content of the robot.txt file and usually update it once a day. If you change the robots.txt file, you can update it quickly via the corresponding tool in Google Search Console.
- Blocking access to a series of site URLs does not mean deleting them from Google’s index. In other words, if you block access to an indexed page by the robot.txt file, that page will still be visible in search results. Below is an example of these pages.
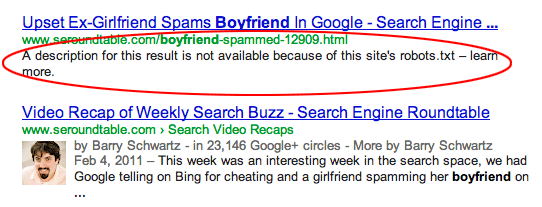
In the image above, Google claims to have such a page, but its information is not visible to Google because it has been blocked. To avoid such a problem, you first need to target the pages using the Navigate Index meta-robots and then block those pages from Google’s index. - Do not block the folders containing the CSS and Javascript required on the website. Because Google is interested in viewing the website in a way that is displayed to users. Google can thus look at the website as mobile.
- It is advisable to have a common set of commands for all user agents so that you do not get confused when updating the robot.txt file.
Robots.txt and WordPress
Everything you learned about therobot.txt file can also be done on WordPress websites. In the past, it was suggested that we block the wp-admin and wp-includes paths in the robot.txt file. But since 2012 no such thing is needed, why the login prompt via @header code (‘X-Robots-Tag: noindex’); Navigation indexes the pages at those addresses.
WordPress does not have a physical file for robot.txt by default, but you will see a text page with the following values in your browser by typing https://www.yourdomain.com/robots.txt:
User-agent: * Disallow: / wp-admin / Allow: /wp-admin/admin-ajax.php
The robot.txtt values are changed to the following values by unchecking the site for search engines in WordPress settings:
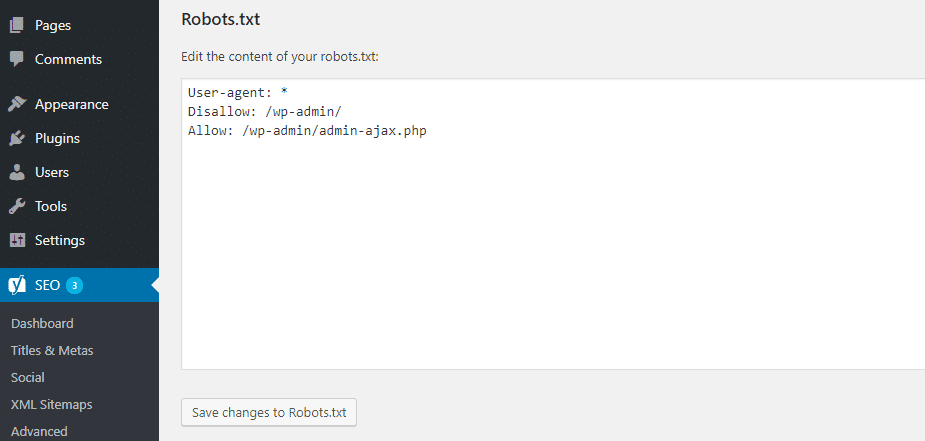
User-agent: * Disallow: /
As you can see, these values block search engine access to the site.
To edit robots.txt in WordPress you must upload a text file of the same name in its root path. This will no longer see the virtual WordPress robot.txt file.
Compare robot.txt, meta robots, and x-robots
There are differences between the above. Robot.txt is a file, while robots and x-robots are metadata. They have different functions from each other. The robots.txt file controls web page monitoring, while meta robots and x-robots manage site indexes in search engines.
Conclusion
It doesn’t take much time to configure the robot.txt file. Build it only once and test it with Google Search Console. Be careful not to hide the screens from the robot’s view. This should only be done at the beginning of the website development and in the future when considering an SEO site.
ABOUT US
Working with Digital marketing, SEO services, and website design with a highly experienced team for years, َAvenger IT Next Generation has been able to meet the needs of people in various businesses and help businesses grow. Continuously updating their level of knowledge and exploring different markets has surpassed the pioneers in this field and incorporate successful experiences into their careers.
Avenger IT Next Generation is a website design and development agency and an SEO agency to promote your business, call with us.
