
Préface: Qu’est-ce qu’un fichier Robots.txt? Quel effet le référencement a-t-il?
Le fichier Robots.txt est un texte que les webmasters peuvent utiliser pour guider les robots des moteurs de recherche lors de la surveillance d’un site Web. Le fichier robot.txt fait partie d’un protocole appelé REP qui standardise la façon dont les robots surveillent le Web et comment accéder et indexer le contenu et le fournir aux utilisateurs. Le protocole REP comprend également comment gérer la balise Meta Robots et d’autres commandes telles que les liens phallus.
En effet, les fichiers texte des robots indiquent aux agents utilisateurs (tels que les robots des moteurs de recherche) les pages à surveiller et les chemins à utiliser. Celles-ci sont données sous forme d’instructions comme Autoriser et Interdire.

Le format de base de ce fichier est le suivant:
User-agent: [user-agent name] Disallow: [URL that should not be monitored]
Ce fichier vous permet d’écrire différentes commandes pour différents agents utilisateurs. Il suffit de distinguer chaque ensemble de commandes pour un agent utilisateur avec un tiret. Remarquez l’image suivante:

Si plusieurs ensembles de commandes sont créés pour plusieurs agents utilisateurs dans le fichier robots.txt, chaque agent utilisateur lit ses instructions. Prenons l’exemple suivant:

Compte tenu des commandes ci-dessus, l’agent utilisateur nommé msnbot ne regarde que l’ensemble des commandes de la partie I. Si l’agent utilisateur connecté au site ne fait partie de ces options, suivez les instructions de la deuxième partie qui ont commencé avec user-agent: * .
Exemples de fichier robots.txt
Voici quelques exemples du fichier texte des robots. Notez que ce fichier se trouve à la racine du site, www.example.com/robots.txt.
Empêcher tous les webmasters d’accéder à l’ensemble du site Web:
User-agent: * Disallow: /
Ces commandes du fichier robots.txt indiquent à tous les navigateurs Web de ne surveiller aucune page du domaine www.example.com.
Accédez à toutes les pages du site pour tous les moniteurs:seo
User-agent: * Disallow:
Ces commandes dans le fichier texte des robots indiquent à tous les navigateurs Web qu’ils peuvent surveiller toutes les pages du domaine www.example.com.
Bloquer l’accès à un moniteur spécifique à partir d’un dossier spécifique:
User-agent: Googlebot Disallow: / example-subfolder /
Ces commandes indiquent à Googlebot Monitor que les URL incluses sur www.example.com/example-subfolder/ ne sont pas surveillées.
Bloquer l’accès à une page Web spécifique à partir d’une page Web particulière:
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Ces commandes indiquent à Bingbot Monitor (Bing Monitor Robot) de ne pas surveiller uniquement l’URL www.example.com/example-subfolder/blocked-page.html.
Comment fonctionne le fichier robots.txt?
Les moteurs de recherche ont deux tâches principales:
- Surveillance Web pour trouver de nouveaux contenus
- Indexation du contenu pour les chercheurs qu’ils recherchent
Les moteurs de recherche pour surveiller les sites Web suivent les liens et vont de site en site. Ce comportement est également appelé exploration ou araignée.
Une fois qu’ils ont atteint un site Web, ils regardent le fichier texte des robots avant de le surveiller. Si vous trouvez ce fichier, lisez-le puis continuez à surveiller le site Web. Les fichiers Robots.txt sont les lignes directrices pour les webmasters pour surveiller le Web. Si le fichier robots.txt n’a aucune commande pour restreindre les chercheurs (ou s’il n’y a aucun fichier robots.txt), les chercheurs indexeront et indexeront toutes les sections trouvées sans aucune restriction.
Informations complémentaires sur le fichier robots.txt
- Le fichier texte des robots doit être situé à la racine du site pour être trouvé par les moniteurs.
- Le fichier Robots.txt est sensible à la casse. Autrement dit, le nom correct de ce fichier est robots.txt. (Les formes comme le texte des robots ne sont pas acceptées)
- Certains robots peuvent remplacer les instructions du fichier texte des robots. C’est plus le cas avec les moniteurs non fiables tels que les robots de recherche d’e-mails.
- Le fichier robots.txt est accessible au public. En d’autres termes, n’importe qui peut voir ses commandes.Alors ne mettez pas vos informations privées là-bas.
- Chaque sous-domaine du site Web doit avoir son fichier texte de robots. En d’autres termes, blog.example.com et example.com doivent chacun avoir leur fichier texte de robots distinct.
- Vous pouvez utiliser le caractère # au début de la description pour insérer un commentaire.
- La taille maximale disponible pour un fichier robots.txt est de 500 Ko. Gardez le volume en dessous de ce nombre.
- Le chemin vers le plan du site peut être placé en bas du fichier texte du robot, comme indiqué ci-dessous.

Nous discuterons de chacun de ces points plus en détail.
Commandes prises en charge dans le fichier robots.txt
Il existe généralement cinq types de commandes pour ce fichier, notamment:
User-agent: fait référence à un moniteur particulier (souvent appelé robots de moteur de recherche). Une liste des agents utilisateurs courants peut être trouvée ici.
Disallow: une commande pour bloquer l’accès à une partie d’un site Web. Une seule instruction Disallow peut être utilisée par ligne.
Allow: cette commande indique à Googlebot qu’il peut accéder à une adresse de sous-répertoire, même si son chemin de collecte principal est bloqué sur une autre ligne du fichier robots.txt.
Crawl-delay: se réfère au temps que le robot doit attendre avant de charger le contenu de la page. Bien sûr, cette commande est souvent ignorée par Google.
Sitemap: fait référence aux plans de site XML. Notez que cette commande n’est prise en charge que par Google, Ask, Bing et Yahoo.
Correspondance de motifs
Les commandes de fichier Robots.txt peuvent également être un peu compliquées lors de la création d’un modèle pour couvrir une plage d’URL. Google et Bing prennent en charge les expressions régulières lorsqu’elles sont utilisées dans un fichier texte de robots, et les experts SEO peuvent les utiliser de manière optimale. Les deux caractères habituels ici sont * et $.
- Caractère * Utilisé pour indiquer l’existence de tout caractère au début, à la fin ou au milieu d’une adresse.
- Le caractère $ est également utilisé pour indiquer la fin d’une URL.
Google a compilé une liste de modèles et d’exemples correspondants ici.
Prioriser les commandes robots.txt
Lorsque plusieurs commandes sont appliquées à une URL, la commande avec le plus de caractères est acceptée. Par exemple, voyons ce qui arrive à l’URL « / home / search / shirts » avec le fichier robot.txt suivant:
Disallow: / home Allow: * search / * Disallow: * shirts
Dans ce scénario, l’URL sera surveillée car la commande Autoriser comporte 9 caractères. Alors que la commande Interdire n’a que 7 caractères. Si vous souhaitez que ce bloc soit bloqué, vous pouvez augmenter les caractères de la commande Interdire comme suit:
Disallow: ******************* / chemises
De plus, si le nombre de caractères est égal, la commande Disallow est prioritaire. Par exemple, « / search / shirts » sera bloqué conformément aux instructions suivantes:
Disallow: / search Allow: * chemises
Où doit se trouver le fichier robots.txt?
Les moteurs de recherche et autres navigateurs Web, après s’être connectés à un site, savent qu’ils doivent rechercher un fichier texte de robots. Mais ils ne recherchent ce fichier que dans un chemin spécifique (la racine du site Web). Si un navigateur Web sur www.example.com/robots.txt ne voit aucun fichier, il suppose qu’il n’y a pas de fichier robots.txt sur ce site Web.
Même si ce fichier existe d’une autre manière, le moniteur ne le remarquera pas. Donc, bien sûr, nous soulignons que vous le mettez à la racine du site Web.
Pourquoi votre site Web a-t-il besoin d’un fichier robots.txt?
Le fichier robots.txt peut être utilisé pour gérer l’accessibilité des moniteurs sur le site Web. Bien que cela puisse être un peu risqué si vous faites une erreur, c’est aussi très efficace.
Certaines des utilisations positives du fichier texte des robots incluent:
- Évitez les problèmes de contenu en double (notez que dans la plupart des scénarios, les méta robots sont la meilleure option)
- Garder une partie du site Web privée (par exemple, section d’administration du site)
- Empêcher l’indexation des pages Web des résultats de recherche internes
- Se référer à la carte du site web
- Empêcher l’indexation de certains fichiers (tels que les PDF) sur le site Web
- Retarder la surveillance du site Web pour éviter une pression excessive sur le serveur Web
- Optimisation du budget d’exploration
S’il n’y a pas de section sur votre site Web pour masquer vos résultats de recherche, il peut être préférable de remplacer le fichier robots.txt.
Éléments cachés par robots.txt
En utilisant le fichier texte des robots, vous pouvez masquer certains liens du site aux moteurs de recherche. Les pages qui peuvent être mentionnées ici sont:
- Pages de contenu en double
- Deuxième page Catégories suivantes
- URL dynamiques de produits ou de catégories
- Pages de profil utilisateur
- Pages d’administration
- Page du panier
- Page de discussion utilisateur
- Page d’action de grâce
- Page de recherche
- Recherchez le fichier robots.txt
Vous n’êtes pas sûr du fichier texte des robots sur votre site Web? Ajoutez simplement le texte de la phrase robots à la fin de votre nom de domaine et entrez l’URL finale dans votre navigateur. Si aucune page de texte n’apparaît, il n’y a pas de fichier de ce type sur votre site.
Comment créer un Fichier robots.txt?
Si le fichier texte des robots n’existe pas sur votre site Web, ne vous inquiétez pas. C’est facile à faire. Vous pouvez uniquement créer un fichier robots.txt sur le site à l’aide de ces commandes, puis le tester à l’aide de l’outil de test de texte des robots du moteur de recherche Google.
Conseils SEO sur le fichier robots.txt
Voici quelques conseils sur la façon de créer un fichier texte de robots qui améliorera le référencement de votre site Web.
- Assurez-vous que le contenu principal du site n’est pas bloqué.
- Les liens vers les pages bloquées par le fichier texte des robots ne seront pas suivis. Cela signifie que s’il n’y a pas de lien vers celui-ci n’importe où ou sur une page non bloquée de votre site Web, il ne sera pas indexé par les moteurs de recherche. Deuxièmement, aucun crédit ne sera transféré de la page bloquée vers ses liens. Si vous avez des pages qui n’ont pas besoin d’être indexées, vous devez rechercher un autre mécanisme.
- N’utilisez jamais un fichier texte de robots pour masquer les données de sites Web sensibles et privés des résultats de recherche. Parce que ces liens peuvent être situés ailleurs sur le site et que les utilisateurs peuvent y accéder. Un meilleur moyen d’empêcher l’accès à ces pages consiste à définir un mot de passe pour l’accès.
- De nombreux moteurs de recherche ont plusieurs agents utilisateurs. Par exemple, Google utilise Googlebot pour la recherche organique. Il utilise également Googlebot-Image pour rechercher des images sur des sites Web. La plupart des agents utilisateurs utilisent un seul moteur de recherche, les mêmes instructions générales pour un agent utilisateur et n’ont pas besoin de définir des commandes différentes pour chacun. Mais si vous avez besoin de définitions de commandes différentes pour différents agents utilisateurs, vous pouvez les définir dans le fichier robots.txt.
- Les moteurs de recherche explorent le contenu du fichier robot.txt et le mettent généralement à jour une fois par jour. Si vous modifiez le fichier robots.txt, vous pouvez le mettre à jour rapidement via l’outil correspondant dans Google Search Console.
- Bloquer l’accès à une série d’URL de sites ne signifie pas les supprimer de l’index de Google. En d’autres termes, si vous bloquez l’accès à une page indexée par le fichier robot.txt, cette page sera toujours visible dans les résultats de la recherche. Voici un exemple de ces pages.
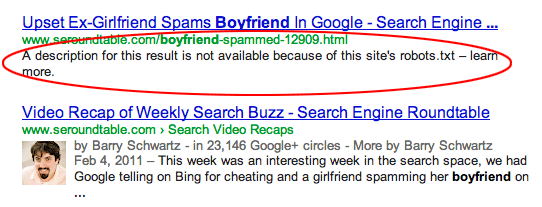
- Dans l’image ci-dessus, Google prétend avoir une telle page, mais ses informations ne sont pas visibles par Google car elles ont été bloquées. Pour éviter un tel problème, vous devez d’abord cibler les pages à l’aide des méta-robots Navigate Index, puis bloquer ces pages de l’index de Google.
Ne bloquez pas les dossiers contenant le CSS et Javascript requis sur le site. Parce que Google souhaite visualiser le site Web d’une manière qui soit affichée aux utilisateurs. Google peut donc considérer le site Web comme mobile. - Il est conseillé d’avoir un ensemble commun de commandes pour tous les agents utilisateurs afin que vous ne soyez pas confus lors de la mise à jour du fichier robot.txt.
Robots.txt et WordPress
Tout ce que vous avez appris sur le fichier therobot.txt peut également être fait sur les sites Web WordPress. Dans le passé, il était suggéré de bloquer les chemins wp-admin et wp-includes dans le fichier robot.txt. Mais depuis 2012, rien de tel n’est nécessaire, pourquoi l’invite de connexion via le code @header (‘X-Robots-Tag: noindex’); La navigation indexe les pages à ces adresses.
WordPress n’a pas de fichier physique pour robot.txt par défaut, mais vous verrez une page de texte avec les valeurs suivantes dans votre navigateur en tapant https://www.votredomaine.com/robots.txt:
User-agent: * Disallow: / wp-admin / Allow: /wp-admin/admin-ajax.php
Les valeurs robot.txtt sont remplacées par les valeurs suivantes en décochant le site pour les moteurs de recherche dans les paramètres WordPress:
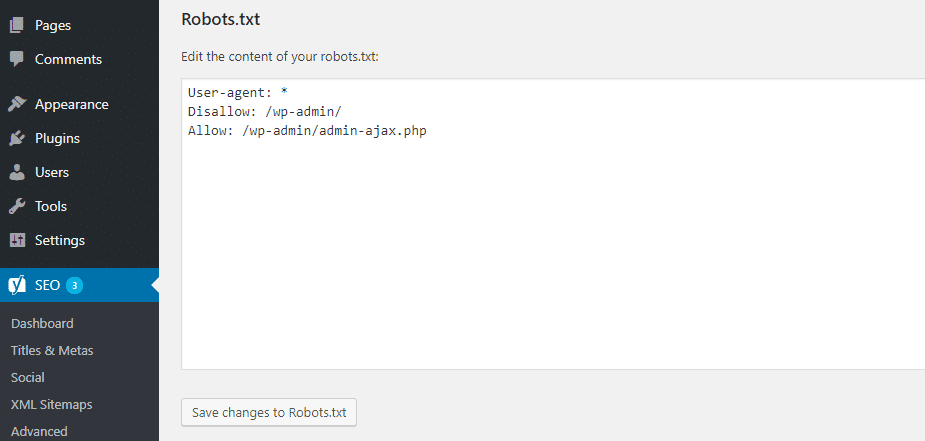
User-agent: * Disallow: /
Comme vous pouvez le voir, ces valeurs bloquent l’accès des moteurs de recherche au site.
Pour modifier robots.txt dans WordPress, vous devez télécharger un fichier texte du même nom dans son chemin racine. Cela ne verra plus le fichier virtuel WordPress robot.txt.
Comparez robot.txt, meta robots et x-robots
Il y a des différences entre ce qui précède. Robot.txt est un fichier, tandis que les robots et les x-robots sont des métadonnées. Ils ont des fonctions différentes les unes des autres. Le fichier robots.txt contrôle la surveillance des pages Web, tandis que les méta robots et x-robots gèrent les index des sites dans les moteurs de recherche.
Conclusion
La configuration du fichier robot.txt ne prend pas beaucoup de temps. Créez-le une seule fois et testez-le avec Google Search Console. Faites attention de ne pas cacher les écrans de la vue du robot. Cela ne devrait être fait qu’au début du développement du site Web et à l’avenir lors de l’examen d’un site de référencement.
À PROPOS DE NOUS
Travaillant avec le marketing numérique, les services de référencement et la conception de sites Web et Migration de services vers PWA avec une équipe très expérimentée depuis des années, Avenger IT Next Generation a été en mesure de répondre aux besoins des personnes dans diverses entreprises et d’aider les entreprises à croître. La mise à jour continue de leur niveau de connaissances et l’exploration de différents marchés ont dépassé les pionniers dans ce domaine et incorporé des expériences réussies dans leur carrière.
Avenger IT Next Generation est une agence de design évolutive et perspicace, techniquement et créativement qualifiée pour traduire votre marque en son meilleur digital. Notre approche de conception et de développement crée des marques percutantes et engageantes et des expériences numériques immersives qui vous apportent un retour sur la créativité, appeler avec nous.
La section des services réseau de Avenger IT Next Generation comprend trois titres principaux:
- Services de conseil et solutions réseau
- Installation et réalisation de projets de réseaux
- Services d’assistance et de maintenance réseau
Ces services prennent la forme de contrats à court et à long terme pour le support et la maintenance du réseau et sous la forme de projets et de cas dans le domaine du conseil et de la mise en œuvre de réseaux aux entreprises, institutions, industries diverses, centres médicaux et éducatifs, grands complexes de bureaux commerciaux, pétrochimie, usines, petites organisations. , Moyen et grand et est fourni.
